|
I am a senior research scientist at Google AI Research, where I work on machine learning for video understanding. I did my PhD with Andrew Zisserman in the VGG group at the University of Oxford, where I was fortunate enough to be funded by a Google PhD Fellowship. My thesis won the ELLIS PhD award. Before that I did my undergrad at the University of Cambridge, where I worked with Roberto Cipolla and Richard Turner.
|

|
|
My research focuses on self-supervised and multi-modal machine learning techniques for video recognition, including the use of sound and text to learn better visual representations. Recently, I have also become interested in computer vision for wildlife conservation. For a full list of publications please see Google Scholar. |
|
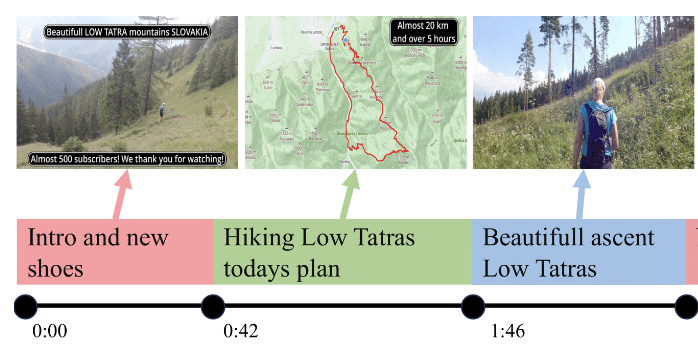
Antoine Yang, Arsha Nagrani, Ivan Laptev, Josef Sivic, Cordelia Schmid NeurIPS (Datasets and Benchmarks), 2023 arXiv / code, models, data, project page New dataset and video-language tasks for video chapterisation in long web videos. |
|
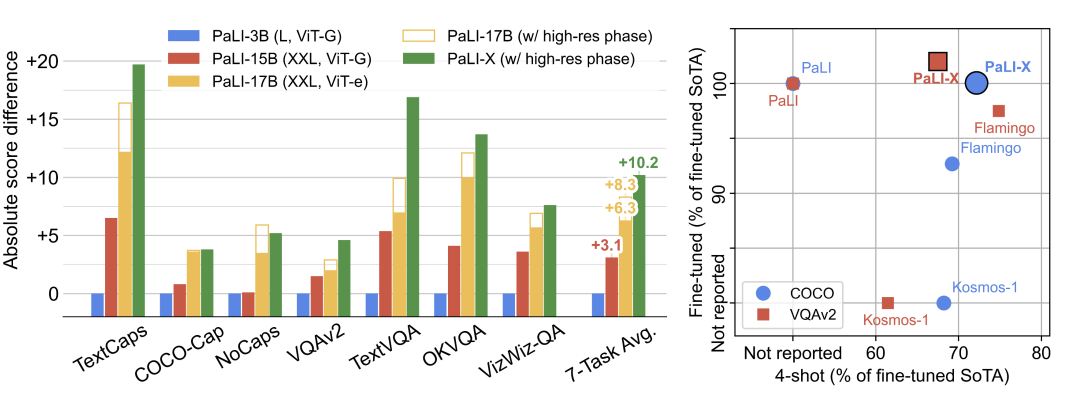
Xi Chen et al. arXiv, 2023 arXiv Scaling up video and language models gives SOTA on 25+ VL benchmarks. |
|
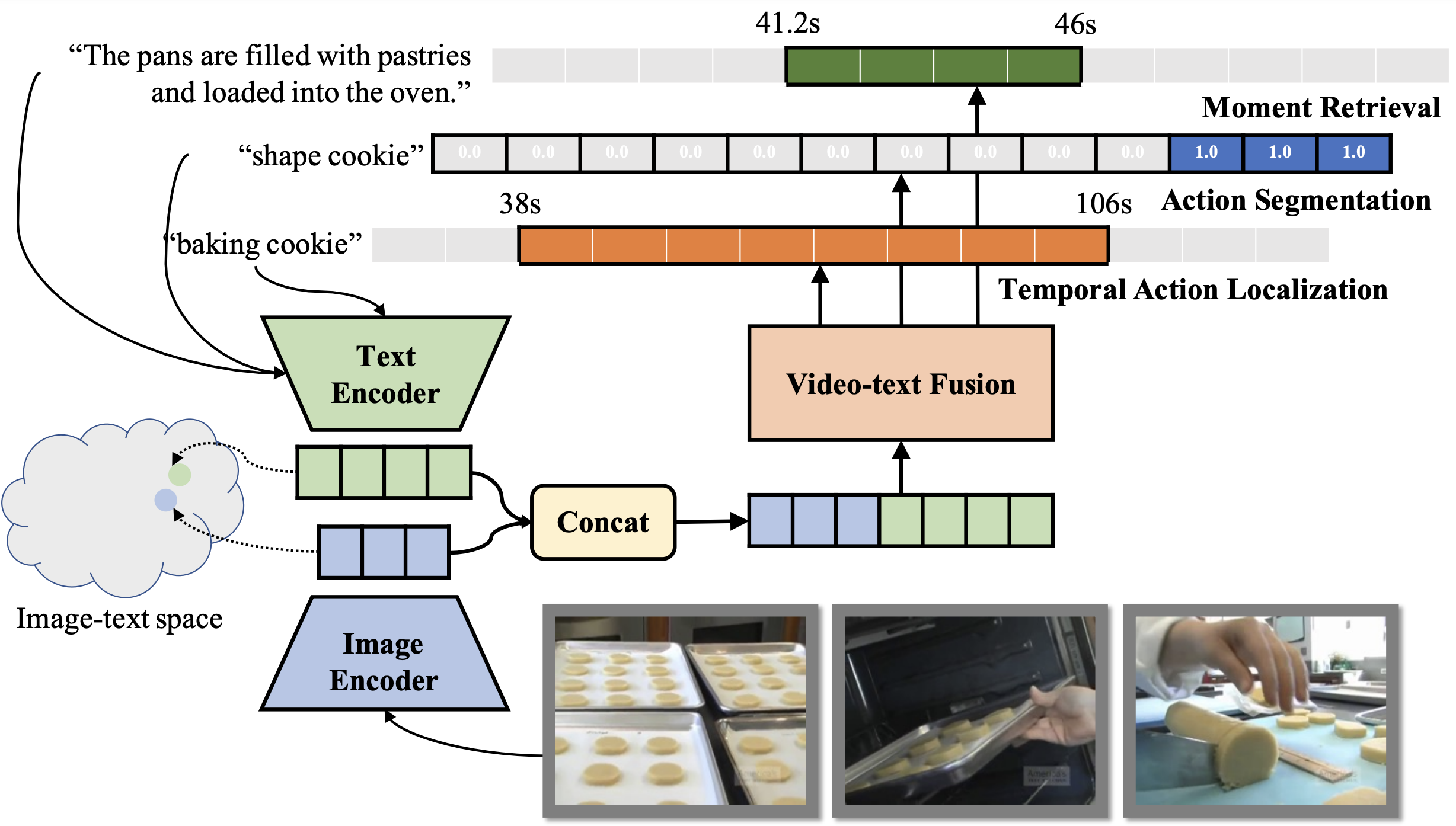
Shen Yan*, Xuehan Xiong*, Arsha Nagrani, Anurag Arnab, Zhonghao Wang, Weina Ge, David Ross, Cordelia Schmid ICCV, 2023 arXiv Image-text models like CLIP can be used for Moment Retrieval, Temporal Localization, and Action Segmentation |
|
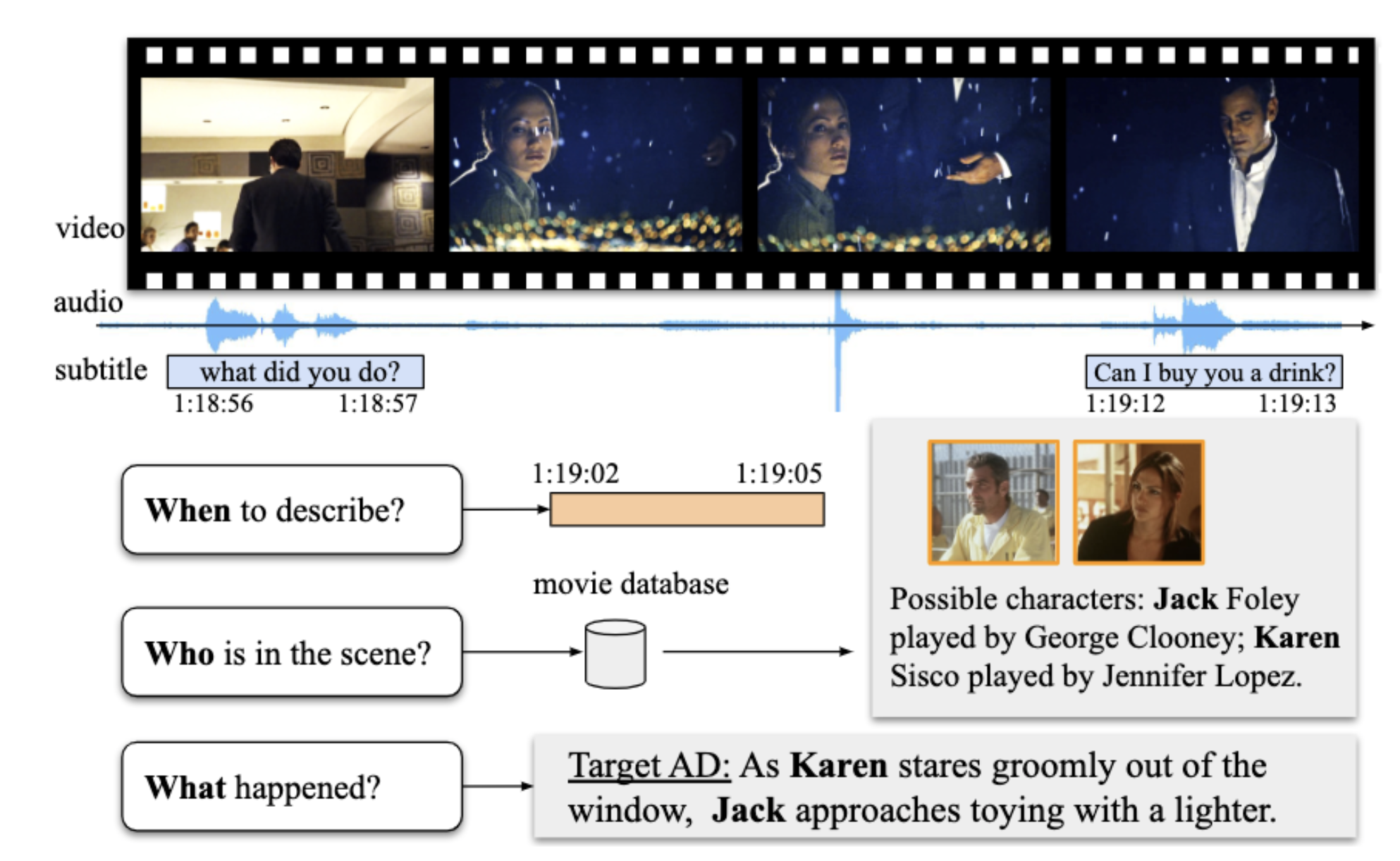
Tengda Han, Max Bain, Arsha Nagrani , Gül Varol, Weidi Xie, Andrew Zisserman ICCV, 2023 Describing visual content in movies (automatic audio descriptions!), focus on character recognition. This is part II, see below for AutoAD I @ CVPR23. |
|
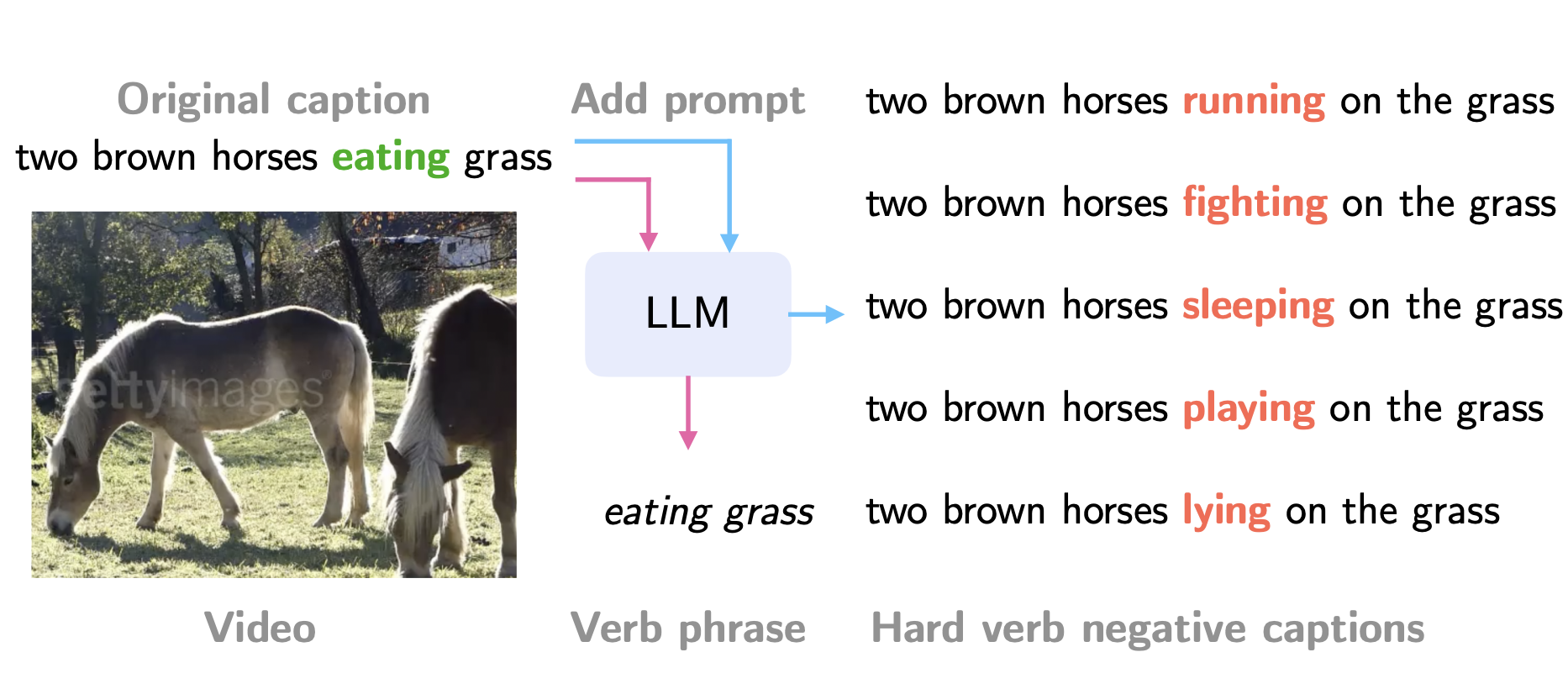
Liliane Momeni, Mathilde Caron, Arsha Nagrani , Andrew Zisserman, Cordelia Schmid ICCV, 2023 arXiv / code Generating better negatives using an LLM can produce a verb-focused video-text model with contrastive training. |
|
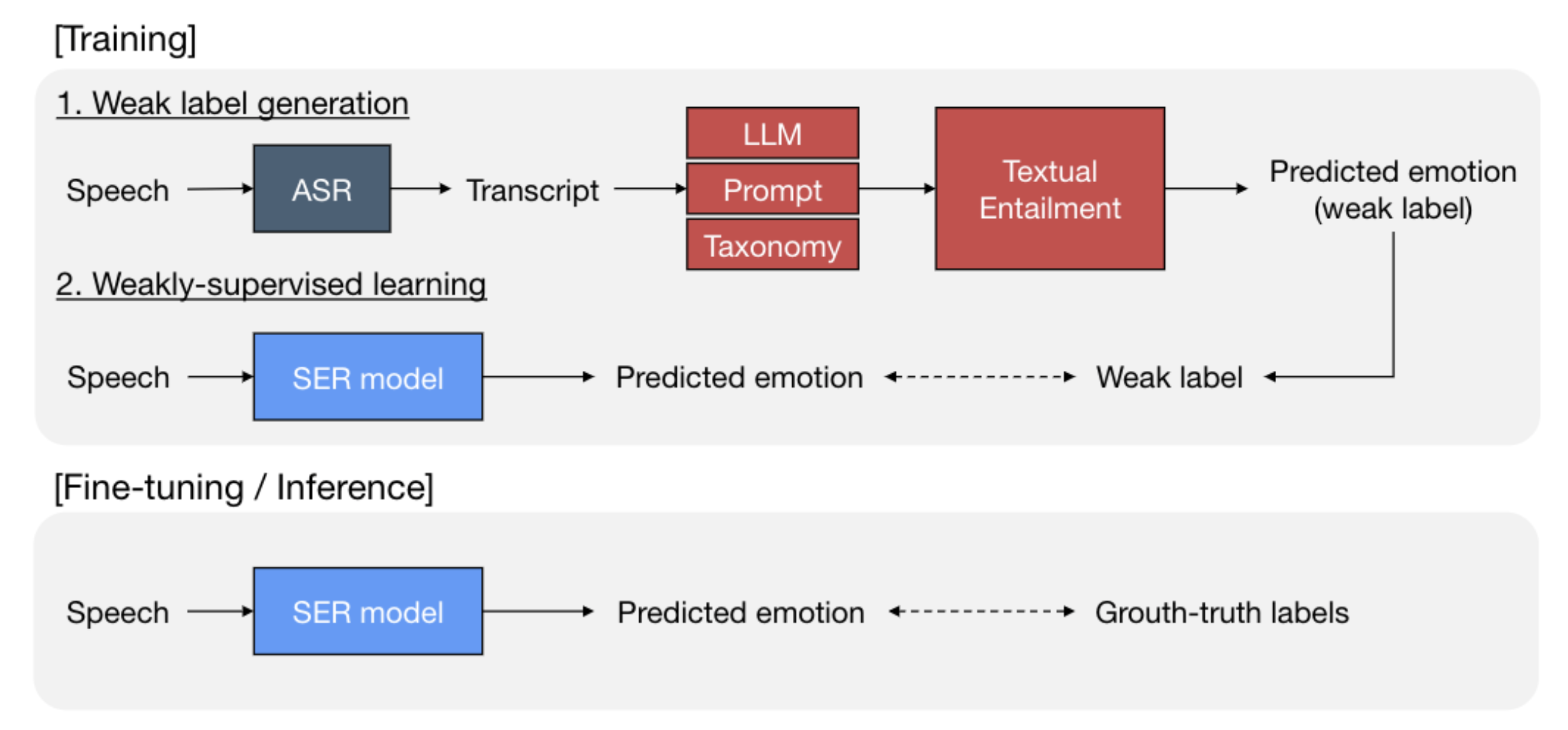
Taesik Gong, Josh Belanich, Krishna Somandepalli, Arsha Nagrani, Brian Eoff, Brendan Jou Interspeech, 2023 PDF. LLMs are used to obtain emotion training data from speech. |

|
Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani , Cordelia Schmid, Andy Zeng, Trevor Darrell, Dan Klein ACL, 2023 arXiv / code / google AI blog LLMs are used to automatically create modular executable code, which is used to solve visual QA. CodeVQA gets SOTA on the COVR and GQA datasets. |
|
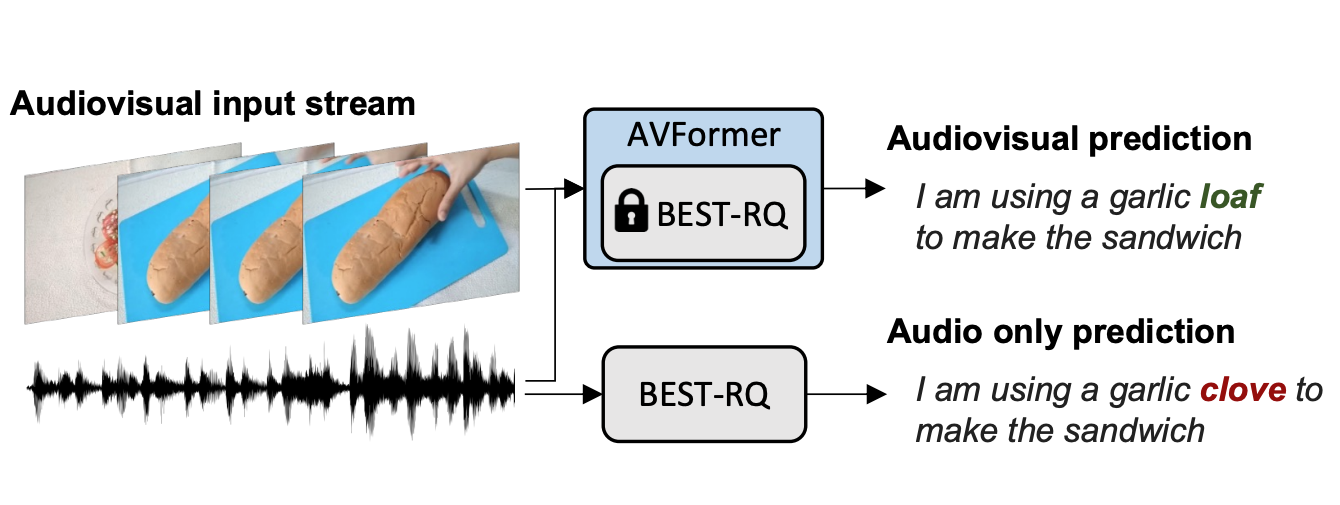
Paul Hongsuck Seo, Arsha Nagrani , Cordelia Schmid CVPR, 2023 arXiv SOTA, zero-shot audiovisual ASR is possible by using lightweight adaptors on top of large frozen unimodal models. |

|
Tengda Han*, Max Bain*, Arsha Nagrani , Gül Varol, Weidi Xie, Andrew Zisserman CVPR, 2023 (Highlight) PDF / project page / code Describing visual content in movies (automatic audio descriptions!) |

|
Antoine Yang, Arsha Nagrani , Paul Hongsuck Seo, Antoine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, and Cordelia Schmid CVPR, 2023 arXiv / project page / code / google AI blog A single-stage, dense event captioning model pretrained on narrated videos at scale achieves SOTA for dense video captioning. |
|
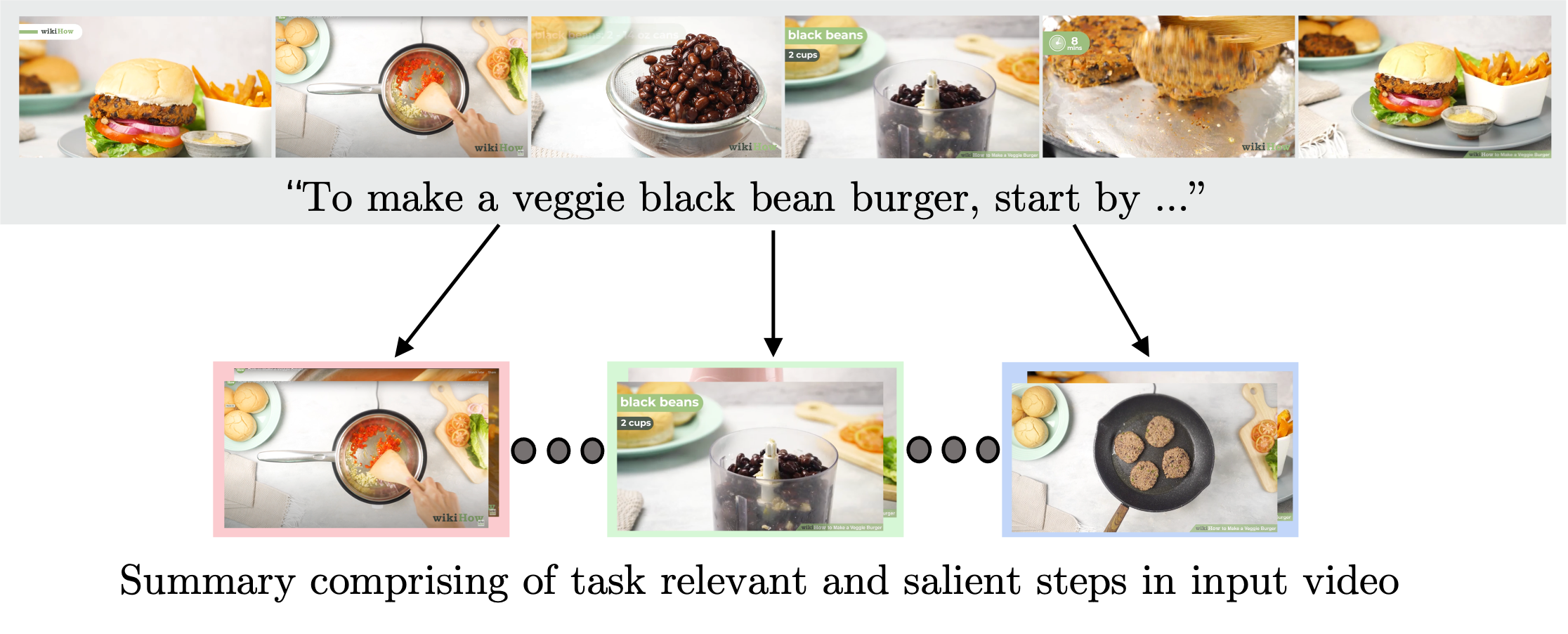
Medhini Narasimhan, Arsha Nagrani , Chen Sun, Miki Rubinstein, Trevor Darrell, Anna Rohrbach, Cordelia Schmid ECCV, 2022 arXiv / project page / code, WikiHow Summaries dataset Creating short video summaries for instructional videos using simple heuristics. New test set released. |
|
|
Valentin Gabeur*, Paul Hongsuck Seo*, Arsha Nagrani*, Chen Sun, Karteek Alahari, Cordelia Schmid Interspeech, 2022 arXiv / project page, visSpeech dataset Visual context (objects, actions) improves ASR performance under challenging audio conditions. |
|
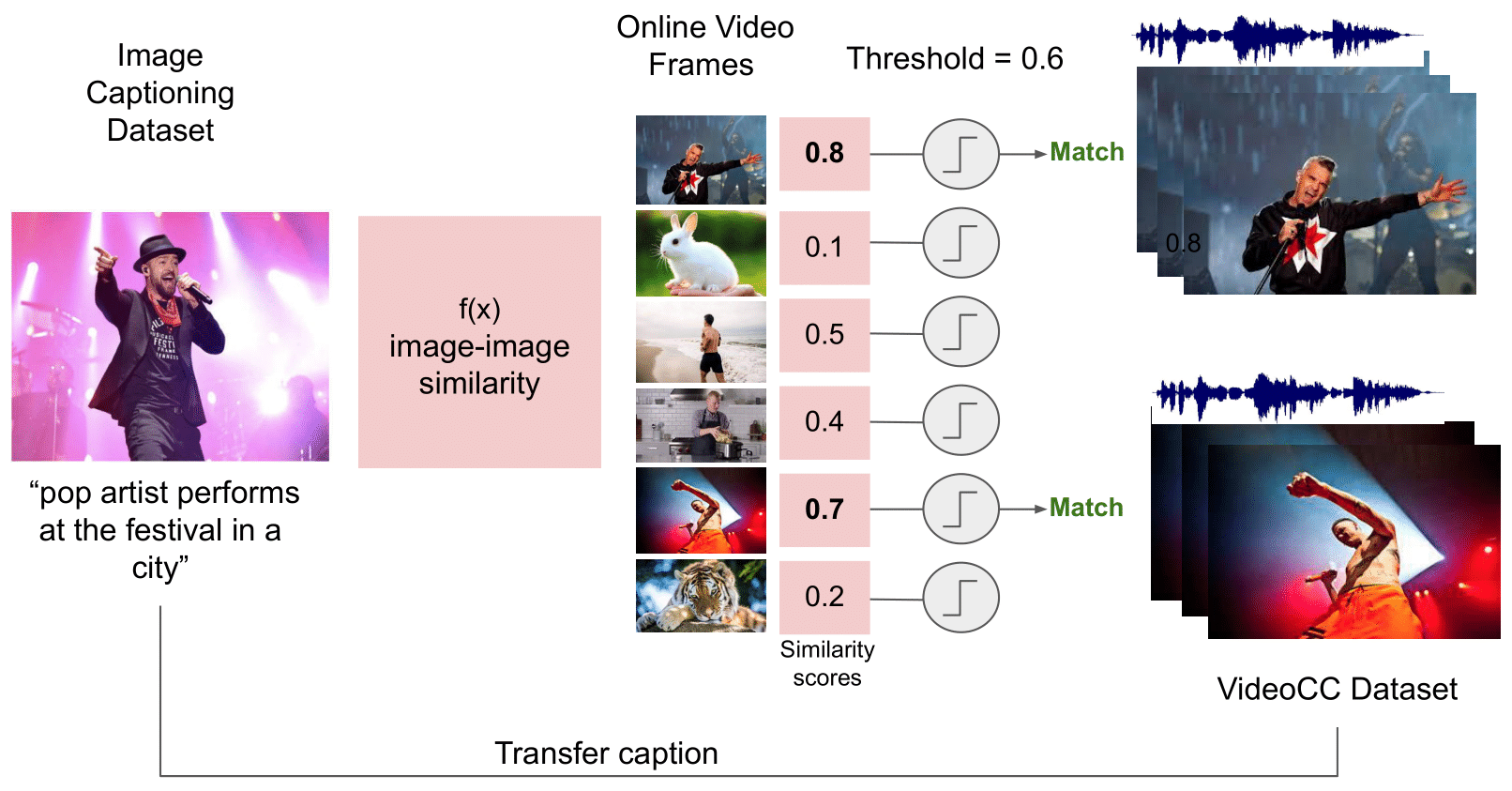
Arsha Nagrani, Paul Hongsuck Seo, Bryan Seybold, Anja Hauth, Santiago Manen, Chen Sun, Cordelia Schmid ECCV, 2022 arXiv / VideoCC dataset Mining audiovisual clips for text captions by leveraging image-image similarity for SOTA video retrieval and captioning. |

|
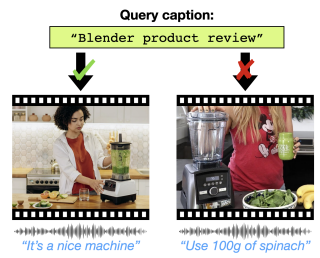
Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab, Cordelia Schmid CVPR, 2022 arXiv New unsupervised pretraining framework for multimodal video captioning that leverages future utterances in unlabelled videos. |
|
Valentin Gabeur, Arsha Nagrani, Chen Sun, Karteek Alahari, Cordelia Schmid WACV, 2022 Video encoder pretraining using appearance, sound, and transcribed speech, by masking out an entire modality and predicting it using the others. |

|
Max Bain, Arsha Nagrani , Daniel Schofield, Sophie Berdugo, Joana Bessa, Jake Owens, Kimberley J. Hockings, Tetsuro Matsuzawa, Misato Hayashi, Dora Biro, Susana Carvalho, Andrew Zisserman Science Advances, 2021 Fully automated, audio-visual pipeline to detect and track two audio-visually distinctive actions in wild chimpanzees: buttress-drumming and nut-cracking. |
|
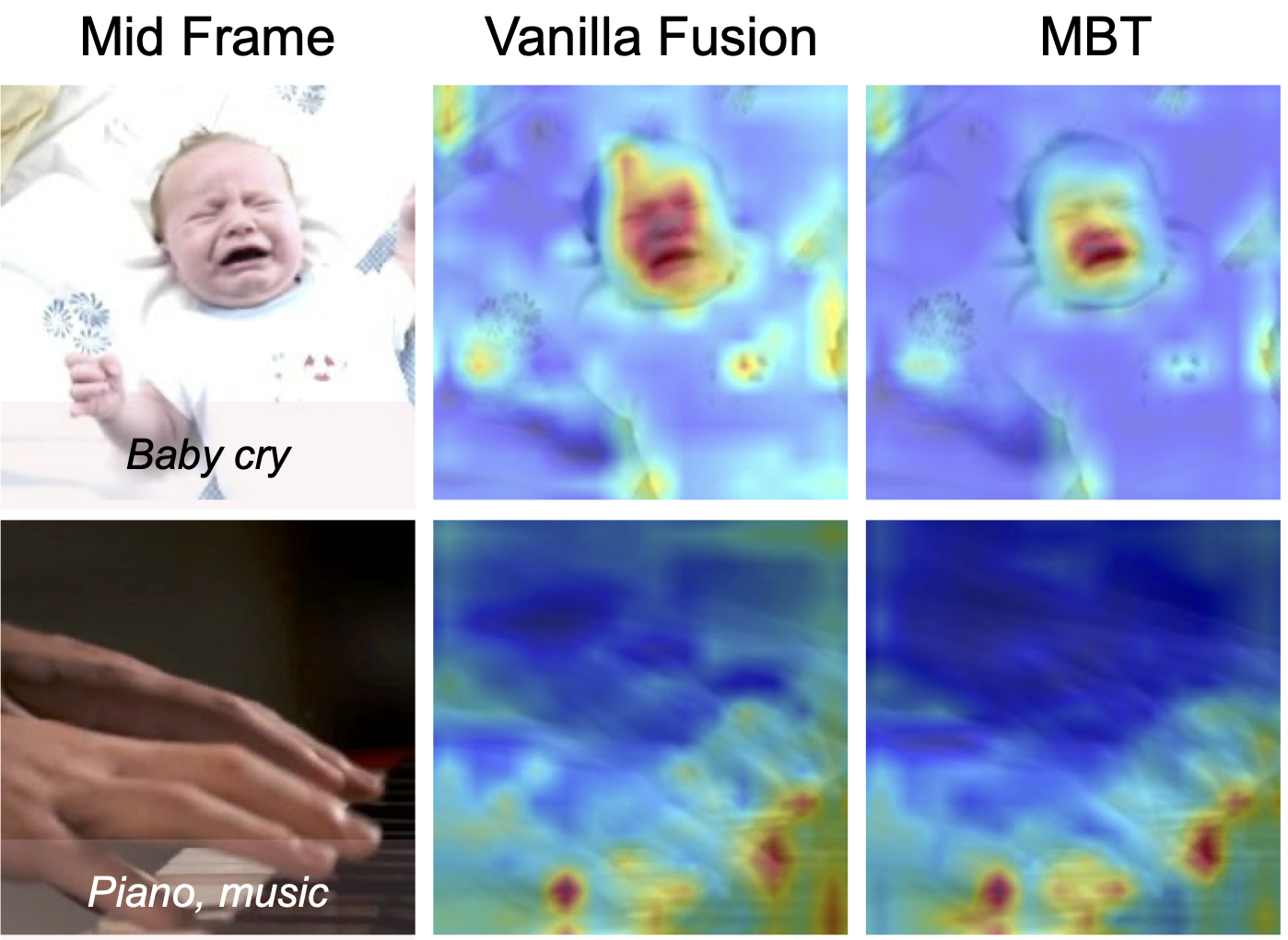
Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, Chen Sun NeurIPS, 2021 arXiv / project page / code / google AI blog Fully transformer based multimodal fusion model gets SOTA on video classification. Attention bottlenecks at multiple layers force cross-modal information to be condensed thereby improving performance at lower computational cost. |
|
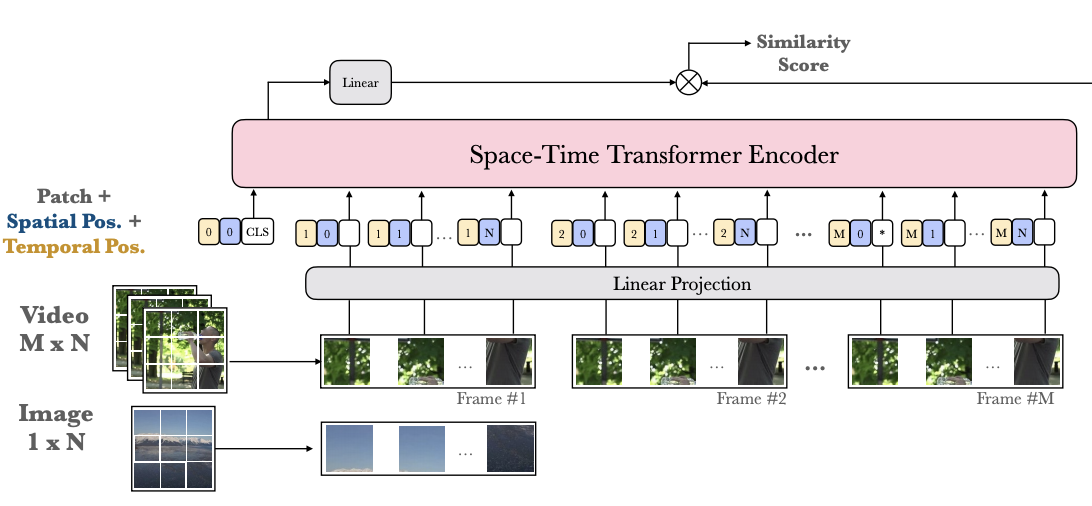
Max Bain, Arsha Nagrani, Gul Varol, Andrew Zisserman ICCV, 2021 arXiv / code, models / WebVid dataset End-to-end encoder for visual retrieval that uses only self-attention blocks. This allows flexible training with variable length videos and images jointly. |
|
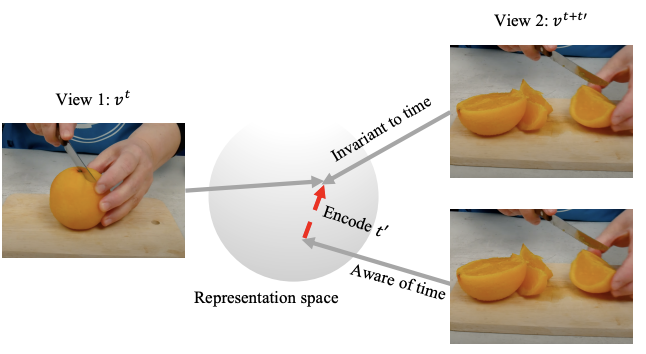
Chen Sun, Arsha Nagrani, Yonglong Tian, Cordelia Schmid ICCV, 2021 arXiv / project page / models Encoding augmentations along with data views gives SOTA on video self-supervised learning benchmarks. |
|
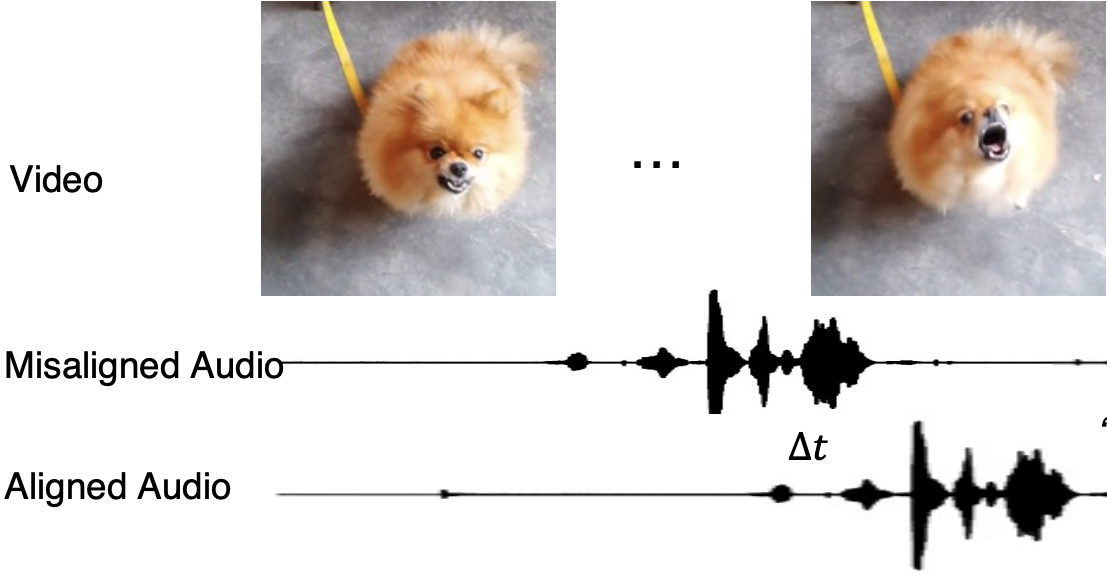
Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Nagrani, Andrea Vedaldi, Andrew Zisserman BMVC, 2021 arXiv / VGGSound-sync data, project page Transformer model for audio-visual synchronization works well on non-speech classes in the wild. |
|
Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Nagrani, Andrea Vedaldi, Andrew Zisserman CVPR, 2021 arXiv / VGG-SS dataset, project page Localizes sounding objects without any supervision using hard negative mining from within the image. Gives SOTA on Flickr SoundNet and a new VGG-SS dataset. |
|
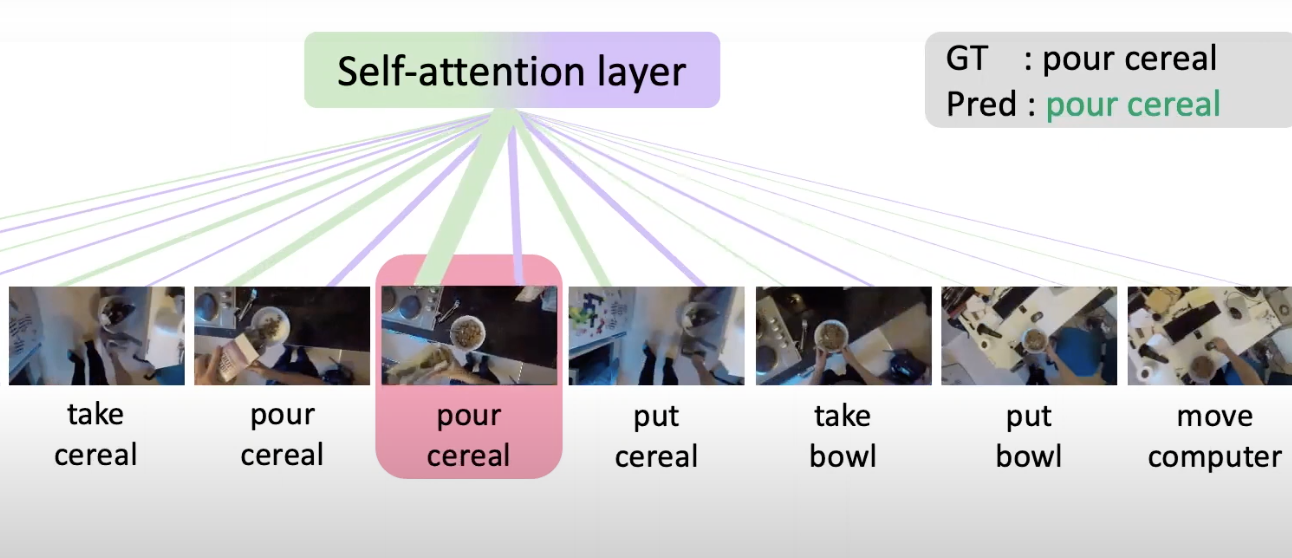
Evangelis Kazakos, Jaesung Huh, Arsha Nagrani, Andrew Zisserman, Dima Damen BMVC, 2021 arXiv / code, models / project page Uses a language model to learn a sequence of actions as temporal context for egocentric action recognition. |

|
Paul Hongsuck Seo, Arsha Nagrani, Cordelia Schmid CVPR, 2021 arXiv / project page Predicting future utterances in a video based on previous dialogue and video frames without manual labels gives SOTA on standard QA datasets. |
|
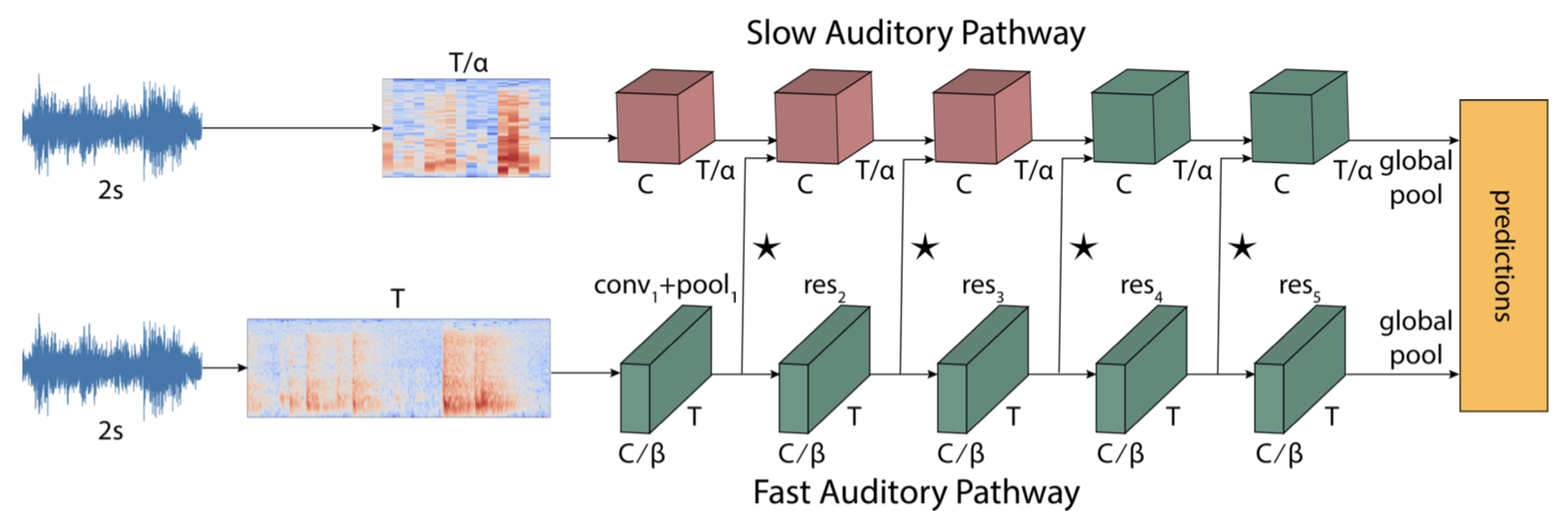
Evangelis Kazakos, Arsha Nagrani, Andrew Zisserman, Dima Damen ICASSP, 2021 (Outstanding Paper Award) arXiv / code, models / project page Two stream audio recognition models that gets SOTA on VGG-Sound and EPIC-Kitchens-100. |
|
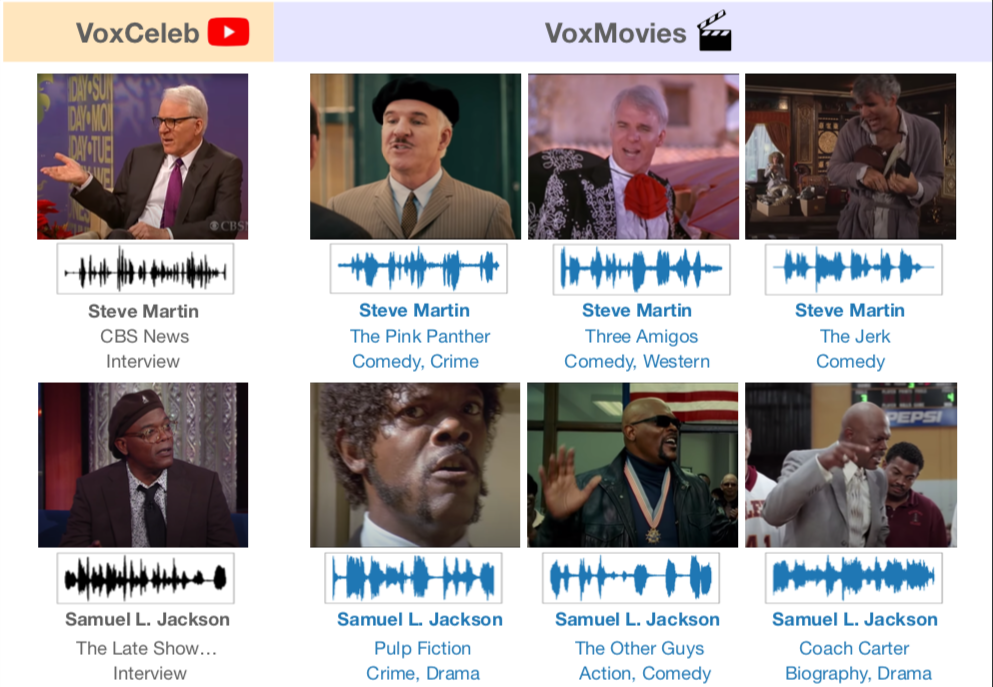
Andrew Brown*, Jaesung Huh*, Arsha Nagrani*, Joon Son Chung, Andrew Zisserman ICASSP, 2021 arXiv / VoxMovies dataset, project page Investigate the performance of speaker recognition in movies, where often actors intentionally disguise their voice to play a character. |

|
Max Bain, Arsha Nagrani, Andrew Brown, Andrew Zisserman ACCV, 2020 (Oral Presentation) project page, CMD dataset / challenge A large-scale story understanding dataset that contains the key scenes from movies with semantic captions. Basis of the CMD Challenge at ICCV 2021. |
|
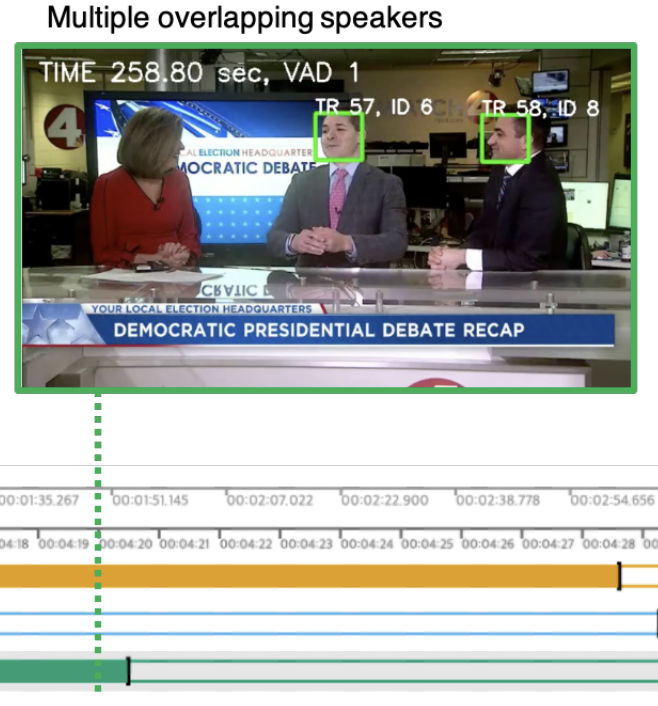
Joon Son Chung*, Jaesung Huh*, Arsha Nagrani*, Triantafyllos Afouras, Andrew Zisserman INTERSPEECH, 2020 project page, VoxConverse dataset / challenge Breaking up multispeaker videos into "who spoke when". Based on this work we are hosting a new speaker diarisation track at the VoxCeleb Speaker Recognition Challenge. |
|
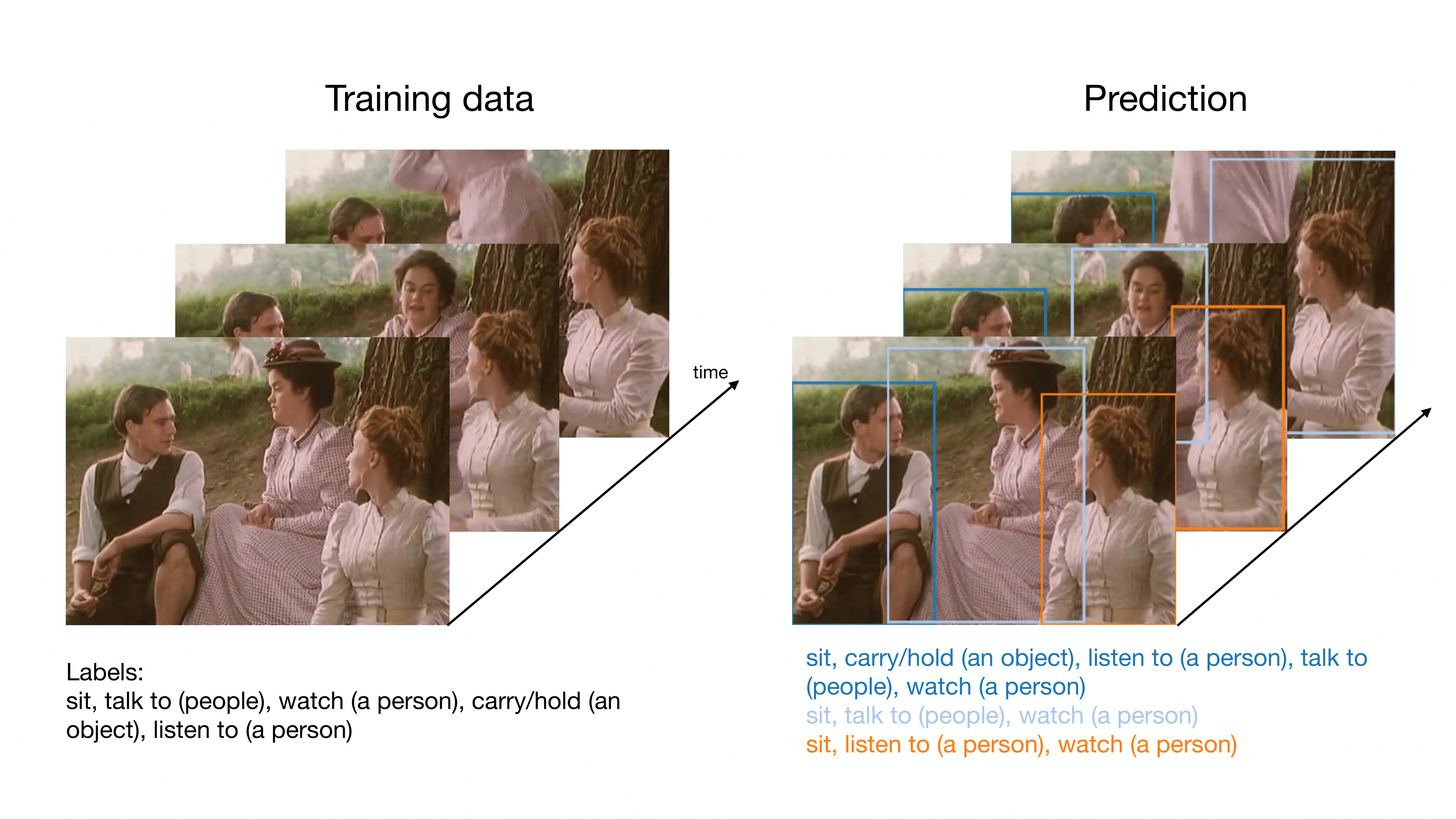
Anurag Arnab, Chen Sun, Arsha Nagrani, Cordelia Schmid ECCV, 2020 arXiv Action localisation in movies using video level labels only. |

|
Arsha Nagrani, Chen Sun, David Ross, Rahul Sukthankar, Cordelia Schmid, Andrew Zisserman CVPR, 2020 project page, data / slides Action recognition in movies using the speech alone. |

|
Arsha Nagrani*, Joon Son Chung*, Samuel Albanie*, Andrew Zisserman ICASSP, 2020 project page / some code Disentanglement of speech embeddings into content and identity with only accompanying facetrack as supervision. Based on this work we are hosting a new self-supervised track at the VoxCeleb Speaker Recognition Challenge. |
|
Arsha Nagrani, Joon Son Chung, Weidi Xie, Andrew Zisserman Computer Speech and Language, 2020 project page, data / code & models / challenge Overview of the VoxCeleb1 and VoxCeleb2 datasets including various updates and splits, and new models for speaker recognition. |

|
Max Bain, Arsha Nagrani, Daniel Schofield, Andrew Zisserman ICCV Workshops, 2019 (Oral Presentation) project page / slides Recognition of wild chimpanzees using full body and full frame CNNs methods. We also release an 'in the wild' video chimpanzee recognition dataset. |

|
Daniel Schofield*, Arsha Nagrani*, Andrew Zisserman, Misato Hayashi, Tetsuro Matsuzawa, Dora Biro, Susana Carvalho Science Advances, 2019 project page Press: New Scientist, MIT Tech Review, TechXplore, Verdict, Digital Trends, Oxford News Face detection, tracking, and recognition of wild chimpanzees from long-term video records using deep CNNs. We also show a brief application for social network analysis. |
|
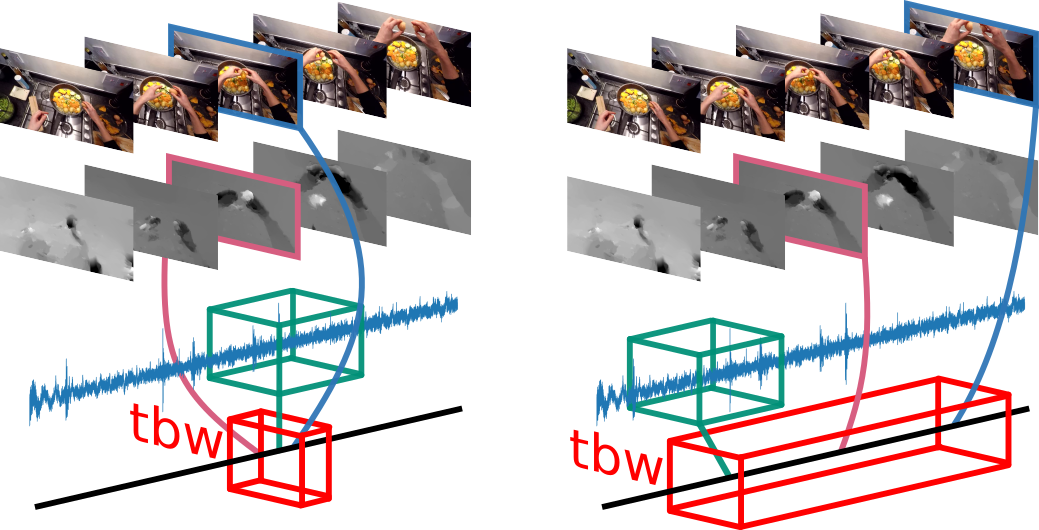
Evangelos Kazakos, Arsha Nagrani, Andrew Zisserman, Dima Damen ICCV, 2019 project page / video / code and models We propose a novel architecture for combining modalities in videos for action recognition, by using a temporal window to allow a range of temporal offsets. |
|
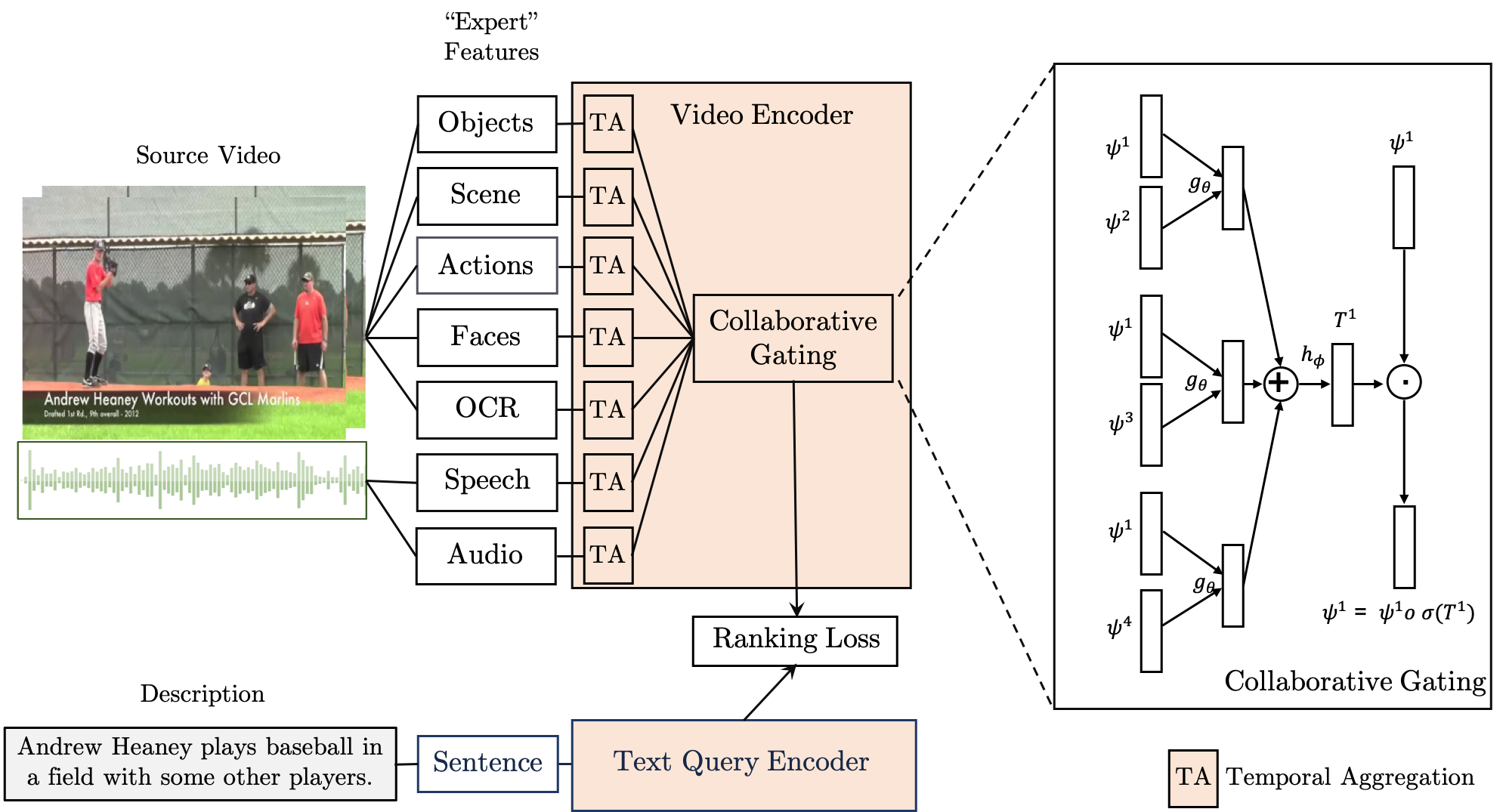
Yang Liu*, Samuel Albanie*, Arsha Nagrani*, Andrew Zisserman BMVC, 2019 project page / code & models / challenge We fuse the information from different embeddings experts for the task of video retrieval - achieving SOTA results on 5 different datasets. This work is also the basis for the Video Pentathlon at CVPR 2020. |
|
|
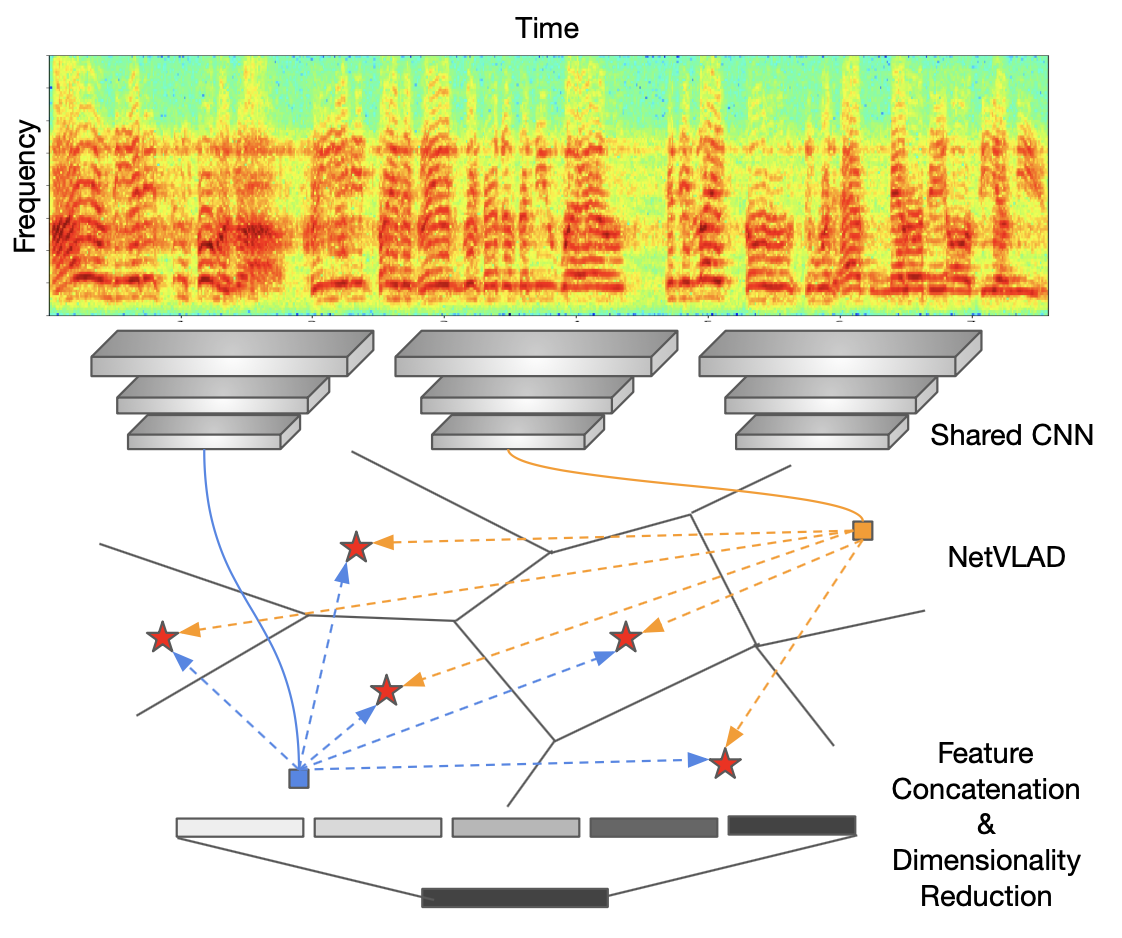
Weidi Xie, Arsha Nagrani, Joon Son Chung, Andrew Zisserman ICASSP, 2019 (Oral Presentation) project page / code & models A NetVlad layer in a deep CNN works well for speaker recognition on long noisy speech utterances. |
 
|
Samuel Albanie*, Arsha Nagrani*, Andrea Vedaldi, Andrew Zisserman ACM Multimedia, 2018 project page / code We use the redundant (common) signal in both audio (speech) and vision (faces) to learn speech representations for emotion recognition without manual supervision. |

|
Joon Son Chung*, Arsha Nagrani*, Andrew Zisserman INTERSPEECH, 2018 data Speaker Recognition in the Wild using deep CNNs. The VoxCeleb datasets are also used integrally in the VoxCeleb Speaker Recognition Challenge. |
|
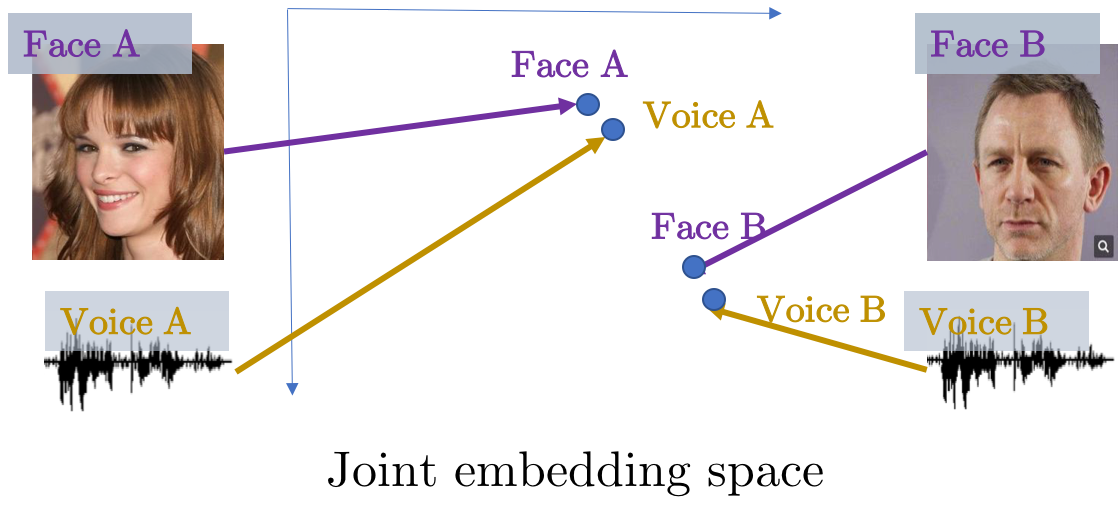
Arsha Nagrani*, Samuel Albanie*, Andrew Zisserman ECCV, 2018 project page We learn joint embedding of faces and voices using cross-modal self-supervision from YouTube videos. |
|
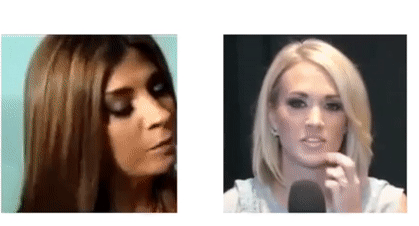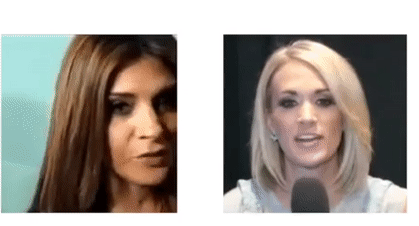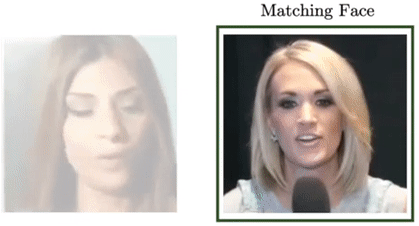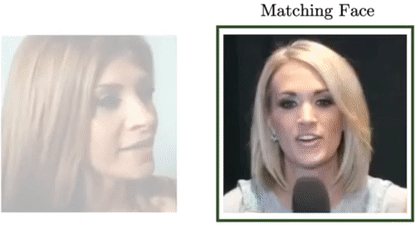
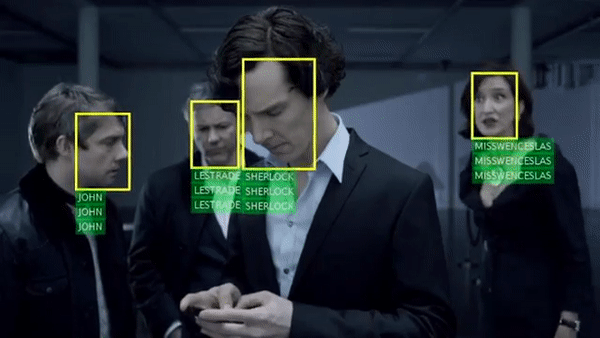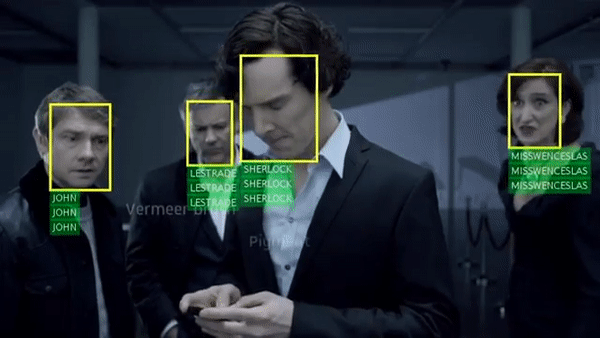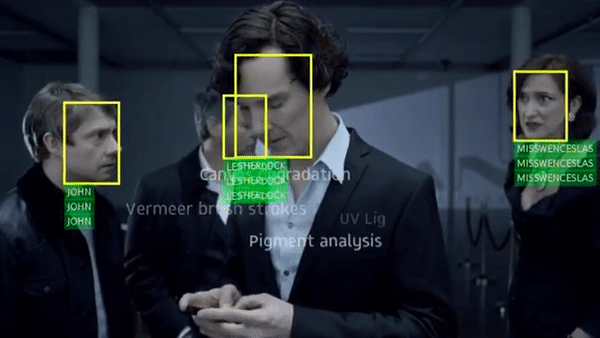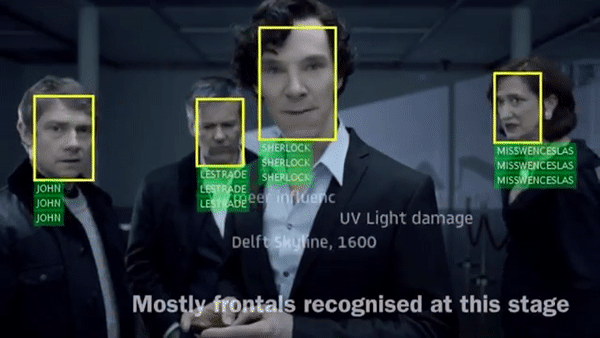
Arsha Nagrani, Samuel Albanie, Andrew Zisserman CVPR, 2018 (Spotlight) project page / video / blog post Can you recognise someone’s face if you have only heard their voice? Or recognise their voice if you have only seen their face? |
|
Arsha Nagrani, Andrew Zisserman BMVC, 2017 (Oral Presentation) project page |
|
Arsha Nagrani*, Joon Son Chung*, Andrew Zisserman INTERSPEECH, 2017 (Oral Presentation, Best Student Paper Award) data / challenge We use face recognition and active speaker detection to automatically create a large scale speaker identification dataset from YouTube videos. |
|
|
|
Area Chair : CVPR23, ICCV23
Reviewer : CVPR, ECCV, ICCV, BMVC, NeurIps, ICML, AAAI, IEEE Triple Access |
| Workshop/Tutorial Organization : Sight and Sound Workshop @ CVPR [2020-2022] website VoxSRC: VoxCeleb Speaker Recognition Challenge @ INTERSPEECH [2021] report / challenge / workshop / data [2020] report / challenge / workshop / data [2019] report / challenge / workshop / data The End-of-End-to-End: A Video Understanding Pentathlon @ CVPR 2020 report / challenge / workshop / recording WICV: Women in Computer Vision Workshop @ CVPR [2020] website / twitter [2019] report / website / twitter |
|
This guy is good at website design. |